基于Hadoop和imposm3来加速OpenStreetMap数据的导入
基于Hadoop和imposm3来加速OpenStreetMap数据的导入
Section titled “基于Hadoop和imposm3来加速OpenStreetMap数据的导入”在基于OpenStreetMap的离线地图建设方案中,osm数据文件需要导入到PostgreSQL中。官方也提供了一些工具来实现这一过程,比如性能相对比较好的 omniscale/imposm3。但问题还是在于OpenStreetMap的全球数据实在忒大,即使采用imposm3也需要数天时间。
于是,我们就需要一种更高效快捷的方式。
二、技术实现方案
Section titled “二、技术实现方案”2.1 默认imposm3的流程
Section titled “2.1 默认imposm3的流程”我们先看一下imposm3的默认流程:
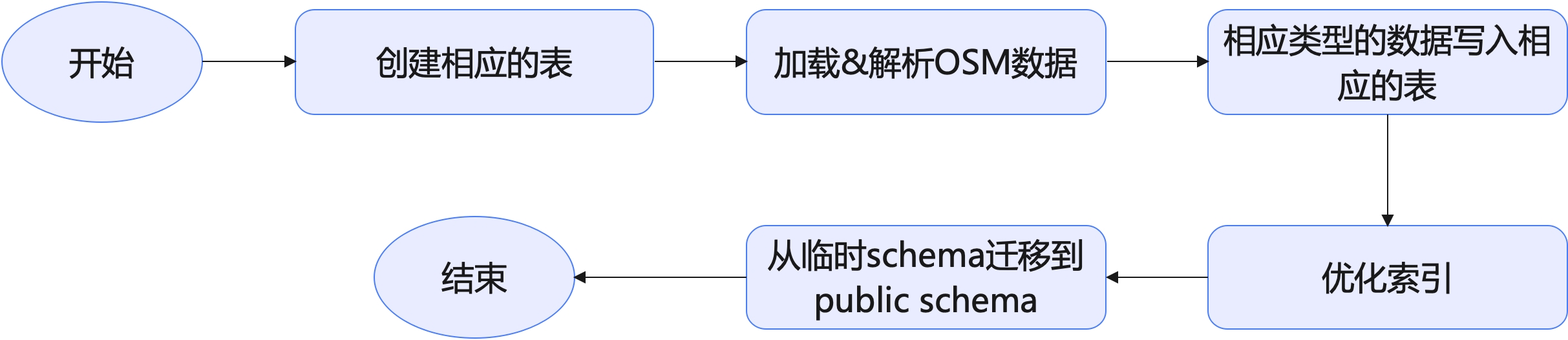
在这个流程中,写入数据的过程其实同时会创建索引。而优化索引是执行了PostgreSQL的CLUSTER和ANALYZE两个语句:
众所周知,创建索引的过程本身就挺慢的,此外,更不幸的是,CLUSTER还会锁表。并且就我的观察而言,数据导入后,大量的时间都花在了CLUSTER这个阶段。虽然,imposm3中的CLUSTER是可选的,可以不传入-optimize参数。但OpenStreetMap的全球数据终究太大了,还是希望能对数据库索引做一些优化的,以达到最佳的性能。
此外,因为imposm3本身是单机版的,在加载&解析OSM数据,并且将解析后的数据导入到PostgreSQL相应表中也是相当地缓慢。
2.2 整体的优化思路
Section titled “2.2 整体的优化思路”我从以下几个阶段来入手:

2.3 并行写入OSM数据
Section titled “2.3 并行写入OSM数据”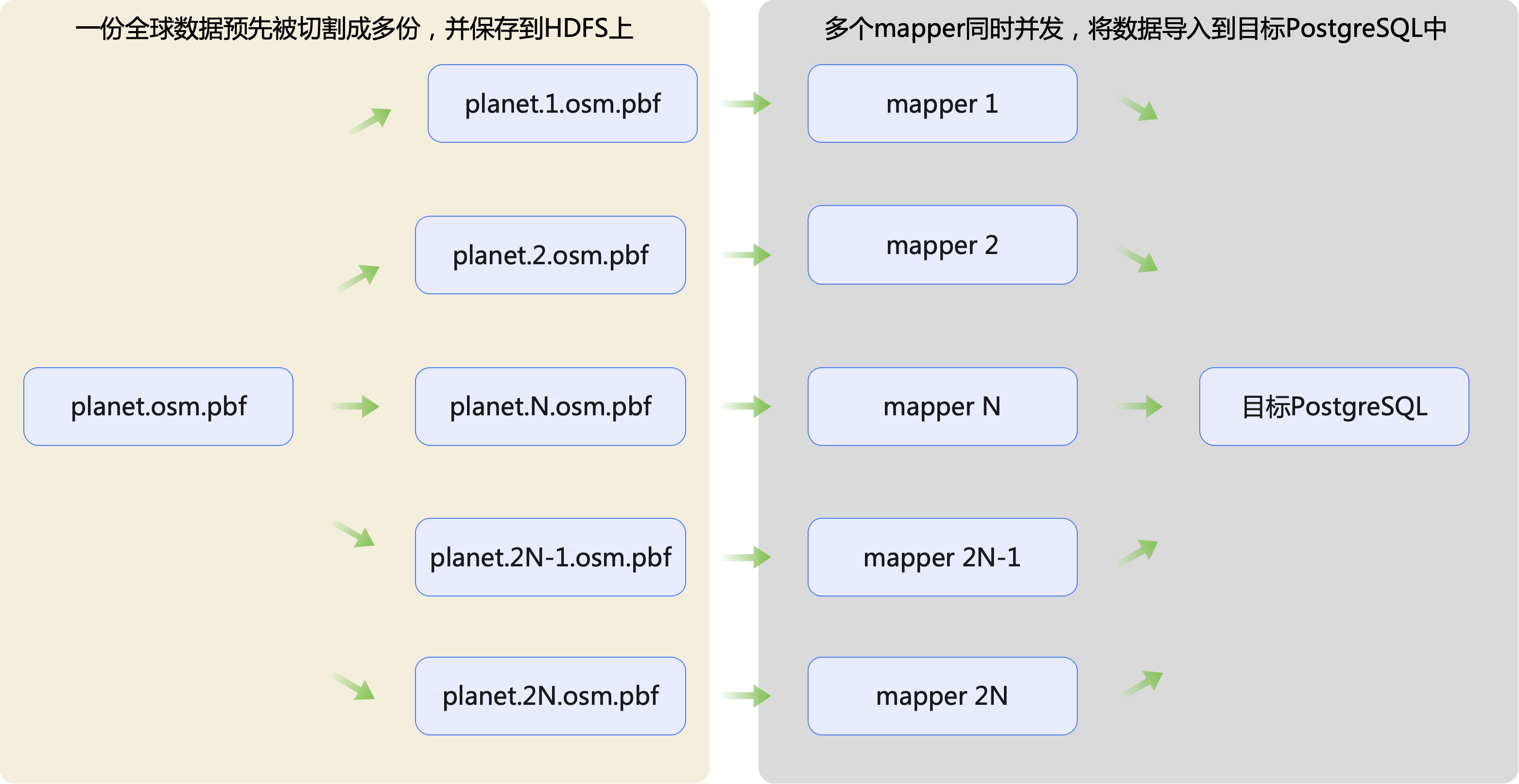
基于上图,这里有以下几个技术点:
- 一份全球planet.osm.pbf如何快速地被切换成多份?
- mapper阶段又如何快速将数据导入到目标PostgreSQL中?
2.3.1 一份全球planet.osm.pbf如何快速地被切换成多份?
Section titled “2.3.1 一份全球planet.osm.pbf如何快速地被切换成多份?”2.3.1.1 切割原则
Section titled “2.3.1.1 切割原则”我们按照什么切割原则来将planet.osm.pbf数据切成多份,有两种方法:
- 方法一:一个最合理的方案其实是按照国境线(如果一个国家面积太大,比如我国、俄罗斯、漂亮国之类的,就按省、州、联邦等二级粒度来切)。
- 方法二:将经纬度按照一定步长来切
这两种方法都可以,并且我都尝试过。
2.3.1.2 按照国境线来切
Section titled “2.3.1.2 按照国境线来切”比较所幸的是:download.geofabrik.de 已经提供了类似类似我上面提到的,把世界切成多个国家、甚至这些面积大的国家按二级粒度来切,我们只要写一个爬虫把这些.osm.pbf抓取下来就行:
#!/usr/bin/env node
const _ = require("lodash");const cheerio = require('cheerio');const axios = require("axios");const {URL} = require('url');const fs = require("fs");const path = require("path");const crypto = require('crypto');const winston = require('winston');const {SingleBar} = require('cli-progress');
const PROXY_PREFIX = ""const INDEX_PAGE = "https://download.geofabrik.de/";
const logger = winston.createLogger({ // 定义日志级别 level: 'info', // 定义日志的格式 format: winston.format.printf(info => `${info.timestamp} ${info.level}: ${info.message}`), // 定义日志的输出 transports: [ // 控制台输出 new winston.transports.Console({ format: winston.format.combine( winston.format.timestamp({ format: 'YYYY-MM-DD HH:mm:ss' }), winston.format.colorize(), winston.format.printf(info => `${info.timestamp} ${info.level}: ${info.message}`) ) }) ]});
async function getPage(url) { while (true) { try { let response = await axios.get(`${PROXY_PREFIX}/${url}`, { rejectUnauthorized: false, userAgent: 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/129.0.0.0 Safari/537.36' }); if (response.status !== 200) { continue; } return response.data;
} catch (e) { } }}
/** * 是否有子区域 */async function hasSubRegions(url) { if (url === INDEX_PAGE) { return true; } const html = await getPage(url); const $ = cheerio.load(html); return $("#subregions").length > 1;}
async function getFinalDownloadUrl(currentUrl) { let osmUrl = { url: "", md5sum: "" } const $ = cheerio.load(await getPage(currentUrl));
$(".download-main a").each((index, element) => { if (osmUrl.url.length > 0) { return; } let $element = $(element); let href = $element.attr("href"); if (href.endsWith(".osm.pbf")) { const fullUrl = new URL(href, currentUrl); osmUrl.url = fullUrl.href; } });
$(".download-main a").each((index, element) => { if (osmUrl.md5sum.length > 0) { return; } let $element = $(element); let href = $element.attr("href"); if (href.endsWith(".osm.pbf.md5")) { osmUrl.md5sum = $element.text(); } });
return osmUrl;}
async function getDownloadUrls(url) { let results = [];
const isLastPage = !await hasSubRegions(url); if (isLastPage) { const finalDownloadUrl = await getFinalDownloadUrl(url); logger.info(`${url} is last page, osm.pbf: ${finalDownloadUrl.url}`); results.push(finalDownloadUrl); return results; }
const html = await getPage(url); const $ = cheerio.load(html); for (const element of $("#subregions:last .subregion a")) { const href = $(element).attr("href"); const fullUrl = new URL(href, url); logger.info(`${url} is index page, goto ${fullUrl.href}`); for (const r of await getDownloadUrls(fullUrl.href)) { results.push(r); } } return results;}
async function downloadFile(url, outputPath) { // 创建一个新的进度条实例 const progressBar = new SingleBar({ format: '下载进度 |{bar}| {percentage}% || {value}/{total} Chunks', barCompleteChar: '\u2588', barIncompleteChar: '\u2591', hideCursor: true });
try { // 发起GET请求 const response = await axios({ method: 'get', url: `${PROXY_PREFIX}/${url}`, responseType: 'stream', rejectUnauthorized: false, userAgent: 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/129.0.0.0 Safari/537.36' });
// 准备写入文件流 const writer = fs.createWriteStream(outputPath);
// 获取内容长度 const totalLength = response.headers['content-length'];
// 初始化进度条 progressBar.start(totalLength, 0);
let receivedLength = 0;
// 监听数据事件 response.data.on('data', (chunk) => { receivedLength += chunk.length; progressBar.update(receivedLength); });
// 数据写入文件 response.data.pipe(writer);
return new Promise((resolve, reject) => { writer.on('finish', () => { progressBar.stop(); resolve(true); });
writer.on('error', (err) => { progressBar.stop(); reject(false); });
// 处理响应错误 response.data.on('error', (err) => { progressBar.stop(); writer.close(); reject(false); }); });
} catch (error) { progressBar.stop(); // 关闭并删除未完成的文件 if (fs.existsSync(outputPath)) { fs.unlinkSync(outputPath); } return false; }}
async function getMD5SUM(filename) { return new Promise((resolve, reject) => { const stream = fs.createReadStream(filename); const hash = crypto.createHash('md5'); stream.on('data', chunk => { hash.update(chunk, 'utf8'); }); stream.on('end', () => { const md5 = hash.digest('hex'); resolve(md5); }); stream.on('error', reject); });}
async function main() { const outputDir = fs.realpathSync(process.argv[2]); if (!fs.existsSync(outputDir)) { fs.mkdirSync(outputDir, {recursive: true, mode: 0o755}); }
const downloads = await getDownloadUrls(INDEX_PAGE); for (const osm of downloads) { logger.info(`Downloading ${osm.url}`); const targetFilename = _.join(_.split(_.replace(_.replace(new URL(osm.url).pathname, /^\//, ""), "-latest", ""), "/"), "-"); const targetFile = path.join(outputDir, targetFilename); while (true) { try { const success = await downloadFile(osm.url, targetFile); if (!success) { continue; } const calValue = await getMD5SUM(targetFile); if (calValue !== osm.md5sum) { logger.error(`${targetFile} md5sum mismatch, expected: ${osm.md5sum}, actual: ${calValue}`); continue; } } catch (e) {} break; }
}}
main().then(async () => { logger.info("下载完成");}).catch((e) => { logger.error(`下载失败: ${e}`);})另外,如果就是想自己切的话,geoboundaries也提供了三级粒度的GeoHash值,直接拿来用就可以了。
#include <iostream>#include <argparse/argparse.hpp>#include <filesystem>#include <fstream>#include <utility>#include <chrono>#include <osmium/io/any_input.hpp>#include <osmium/io/any_output.hpp>#include <osmium/io/reader_with_progress_bar.hpp>#include <osmium/io/writer.hpp>#include <osmium/io/pbf_input.hpp>#include <osmium/util/progress_bar.hpp>#include <osmium/util/verbose_output.hpp>#include <osmium/util/file.hpp>#include <osmium/index/map/all.hpp>#include <osmium/handler/node_locations_for_ways.hpp>#include <osmium/geom/haversine.hpp>#include <osmium/area/assembler.hpp>#include <osmium/area/multipolygon_manager.hpp>#include <osmium/area/assembler.hpp>#include <osmium/area/multipolygon_collector.hpp>#include <osmium/builder/osm_object_builder.hpp>#include <osmium/handler/node_locations_for_ways.hpp>#include <osmium/index/map/sparse_mem_array.hpp>#include <osmium/io/any_input.hpp>#include <osmium/io/file.hpp>#include <osmium/memory/buffer.hpp>#include <osmium/index/map/dense_file_array.hpp>#include <nlohmann/json.hpp>#include <osmium/geom/coordinates.hpp>#include <osmium/visitor.hpp>#include <spdlog/spdlog.h>#include <cstdlib>#include <random>#include <fmt/core.h>#include <thread>#include <mutex>#include <cmath>#include <boost/geometry.hpp>#include <boost/geometry/geometries/point.hpp>#include <boost/geometry/geometries/polygon.hpp>#include <boost/algorithm/string.hpp>
using json = nlohmann::json;using index_type = osmium::index::map::SparseFileArray<osmium::unsigned_object_id_type, osmium::Location>;using location_handler_type = osmium::handler::NodeLocationsForWays<index_type>;namespace bg = boost::geometry;typedef bg::model::point<double, 2, bg::cs::cartesian> Point;typedef bg::model::polygon<Point> Polygon;
enum ADMLevel { ADM0 = 0, ADM1, ADM2, ADM99,};
class IGeoJSONFeature {public: virtual bool contains(double x, double y) = 0;
virtual std::string get_shape_name() = 0;
virtual ADMLevel get_adm_level() = 0;
public: virtual ~IGeoJSONFeature() {};};
class InnerGeoJSONFeature : public IGeoJSONFeature {public: ADMLevel admLevel; std::string shapeName; std::vector<Polygon *> coordinates;
public: virtual ~InnerGeoJSONFeature() {};
public: bool contains(double x, double y) override { Point p(x, y); bool inside = false; for (Polygon *iter: coordinates) { if (bg::within(p, *iter)) { inside = true; break; } } return inside; }
std::string get_shape_name() override { return shapeName; }
ADMLevel get_adm_level() override { return admLevel; }};
class OuterGeoJSONFeature : public IGeoJSONFeature {public: ADMLevel admLevel{ADM99}; std::string shapeName{"others"}; std::vector<Polygon *> coordinates;
public: virtual ~OuterGeoJSONFeature() {}
public: bool contains(double x, double y) override { Point p(x, y); bool inside = false; for (Polygon *iter: coordinates) { if (bg::within(p, *iter)) { inside = true; break; } } return !inside; }
std::string get_shape_name() override { return shapeName; }
ADMLevel get_adm_level() override { return admLevel; }};
void parse_geojson(const std::string &geojson_path, ADMLevel admLevel, std::vector<IGeoJSONFeature *> *geoJsonFeatures) { std::ifstream geojson_file(geojson_path); json geojson; geojson_file >> geojson;
for (auto &feature: geojson["features"]) { InnerGeoJSONFeature *geoJsonFeature = new InnerGeoJSONFeature(); geoJsonFeatures->push_back(geoJsonFeature); geoJsonFeature->admLevel = admLevel; geoJsonFeature->shapeName = feature["properties"]["shapeName"]; auto &geometry = feature["geometry"]; if (geometry["type"] == "Polygon") { Polygon *polygon = new Polygon(); for (auto &level1: geometry["coordinates"]) { for (auto &level2: level1) { bg::append(polygon->outer(), Point(level2[0], level2[1])); } } bg::correct(*polygon); geoJsonFeature->coordinates.push_back(polygon); } else if (geometry["type"] == "MultiPolygon") { for (auto &level0: geometry["coordinates"]) { Polygon *polygon = new Polygon(); for (auto &level1: level0) { for (auto &level2: level1) { bg::append(polygon->outer(), Point(level2[0], level2[1])); } } bg::correct(*polygon); geoJsonFeature->coordinates.push_back(polygon); } } } geojson_file.close();}
std::string join_paths(const std::string &path1, const std::string &path2) { if (path1.empty()) return path2; if (path2.empty()) return path1;
std::filesystem::path p1(path1); std::filesystem::path p2(path2); return (p1 / p2).string();}
class CacheLocationHandler : public osmium::handler::Handler {private: location_handler_type &location_handler;public: CacheLocationHandler(location_handler_type &loc_handler) : location_handler(loc_handler) { }
void node(const osmium::Node &node) { osmium::Location location = node.location(); if (!location.valid()) { return; } location_handler.node(node); }
void way(const osmium::Way &way) { if (way.nodes().empty()) { return; } location_handler.way(const_cast<osmium::Way &>(way)); }
void relation(const osmium::Relation &relation) { if (relation.members().empty()) { return; } location_handler.relation(relation); }};
class MultiWriterHandler : public osmium::handler::Handler {private: std::vector<IGeoJSONFeature *> primary_features; std::vector<IGeoJSONFeature *> secondary_features; std::vector<IGeoJSONFeature *> other_features;; std::vector<osmium::io::Writer *> primary_writers; std::vector<osmium::io::Writer *> secondary_writers; std::vector<osmium::io::Writer *> other_writers; location_handler_type &location_handler;
public: MultiWriterHandler( const std::int32_t thread_id, const std::vector<std::string> &output_dirs, const std::vector<IGeoJSONFeature *> *features, location_handler_type &loc_handler ) : location_handler(loc_handler) {
for (const auto &feature: *features) { if (feature->get_adm_level() == ADM0) { primary_features.push_back(feature); } else if (feature->get_adm_level() == ADM1) { secondary_features.push_back(feature); } else if (feature->get_adm_level() == ADM99) { other_features.push_back(feature); } }
std::random_device rd; // 随机数设备 std::default_random_engine eng(rd()); // 随机数引擎 std::uniform_int_distribution<> distr(0, output_dirs.size() - 1);
for (const auto &feature: primary_features) { std::string shape_name = feature->get_shape_name(); boost::replace_all(shape_name, " ", "-"); std::string pbf_filename = fmt::format("{}_{}.osm.pbf", shape_name, thread_id); this->primary_writers.push_back(new osmium::io::Writer(join_paths(output_dirs[distr(eng)], pbf_filename), osmium::io::overwrite::allow)); } for (const auto &feature: secondary_features) { std::string shape_name = feature->get_shape_name(); boost::replace_all(shape_name, " ", "-"); std::string pbf_filename = fmt::format("{}_{}.osm.pbf", shape_name, thread_id); this->secondary_writers.push_back(new osmium::io::Writer(join_paths(output_dirs[distr(eng)], pbf_filename), osmium::io::overwrite::allow)); } for (const auto &feature: other_features) { std::string pbf_filename = fmt::format("{}_{}.osm.pbf", feature->get_shape_name(), thread_id); this->other_writers.push_back(new osmium::io::Writer(join_paths(output_dirs[distr(eng)], pbf_filename), osmium::io::overwrite::allow)); } }
~MultiWriterHandler() { for (auto &writer: primary_writers) { writer->close(); delete writer; } for (auto &writer: secondary_writers) { writer->close(); delete writer; } for (auto &writer: other_writers) { writer->close(); delete writer; } }
bool pick_to_basket(const osmium::Location &location, const osmium::OSMObject &object) { if (!location.valid()) { return false; } double lon = location.lon(); double lat = location.lat(); for (std::size_t i = 0; i < secondary_features.size(); i++) { IGeoJSONFeature *feature = secondary_features.at(i); if (feature->contains(lon, lat)) { (*secondary_writers[i])(object); return true; } }
for (std::size_t i = 0; i < primary_features.size(); i++) { IGeoJSONFeature *feature = primary_features.at(i); if (feature->contains(lon, lat)) { (*primary_writers[i])(object); return true; } }
// for (std::size_t i = 0; i < other_features.size(); i++) {// IGeoJSONFeature *feature = other_features.at(i);// if (feature->contains(lon, lat)) {// (*other_writers[i])(object);// return true;// }// } return false; }
void node(const osmium::Node &node) { osmium::Location location = node.location();// auto start = std::chrono::system_clock::now(); pick_to_basket(location, node);// auto end = std::chrono::system_clock::now();// SPDLOG_INFO("pick node: {}, speed: {} ms", node.id(), std::chrono::duration_cast<std::chrono::milliseconds>(end - start).count()); }
void way(const osmium::Way &way) { if (way.nodes().empty()) { return; }// auto start = std::chrono::system_clock::now(); for (const auto &node_ref: way.nodes()) { osmium::Location loc = location_handler.get_node_location(node_ref.ref()); bool picked = pick_to_basket(loc, way); if (picked) { break; } }// auto end = std::chrono::system_clock::now();// SPDLOG_INFO("pick way: {}, speed: {} ms", way.id(), std::chrono::duration_cast<std::chrono::milliseconds>(end - start).count()); }
void relation(const osmium::Relation &relation) { if (relation.members().empty()) { return; }// auto start = std::chrono::system_clock::now(); for (const auto &member: relation.members()) { if (member.type() == osmium::item_type::node || member.type() == osmium::item_type::way) { osmium::Location loc = location_handler.get_node_location(member.ref()); if (pick_to_basket(loc, relation)) { break; } } }// auto end = std::chrono::system_clock::now();// SPDLOG_INFO("pick relation: {}, speed: {} ms", relation.id(), std::chrono::duration_cast<std::chrono::milliseconds>(end - start).count()); }};
void process_boxes_chunk( const std::int32_t thread_id, const std::vector<std::string> &output_dirs, location_handler_type &location_handler, const std::vector<IGeoJSONFeature *> &features_chunk, const std::string &input_pbf, std::mutex &output_mutex) { osmium::io::File input_file(input_pbf); osmium::io::Reader reader(input_file, osmium::osm_entity_bits::all); osmium::io::Header header; MultiWriterHandler handler(thread_id, output_dirs, &features_chunk, location_handler); osmium::apply(reader, handler); reader.close();
std::lock_guard<std::mutex> lock(output_mutex);}
int main(int argc, char *argv[]) { spdlog::set_level(spdlog::level::info); spdlog::set_pattern("%+");
argparse::ArgumentParser program("按照bbox范围切割.osm.pbf文件");
program.add_argument("--input") .required() .help("输入 PBF 文件路径");
program.add_argument("--output-dir") .required() .nargs(argparse::nargs_pattern::at_least_one) .help("输出文件的目录,支持多个目录");
program.add_argument("--geojson") .required() .nargs(argparse::nargs_pattern::at_least_one) .help("GEOJSON文件"); program.add_argument("--threads-num").scan<'i', int>().default_value(20).help("线程数");
program.add_argument("--use-cache").default_value(false).implicit_value(true).help("是否使用缓存"); program.add_argument("--index-file").help("索引文件路径");
try { program.parse_args(argc, argv); } catch (const std::runtime_error &err) { std::cerr << err.what() << std::endl; std::cerr << program; return EXIT_FAILURE; }
std::string input_pbf = program.get<std::string>("--input"); std::vector<std::string> output_dirs = program.get<std::vector<std::string>>("--output-dir"); std::vector<std::string> geojson_files = program.get<std::vector<std::string>>("--geojson"); int threads_num = program.get<int>("--threads-num"); bool use_cache = program.get<bool>("--use-cache"); std::string index_path; if (use_cache) { index_path = program.get<std::string>("--index-file"); if (!std::filesystem::exists(index_path)) { SPDLOG_ERROR("索引文件: {} 不存在", index_path); return EXIT_FAILURE; } } else { index_path = join_paths(output_dirs.at(0), "index.idx"); if (std::filesystem::exists(index_path)) { std::remove(index_path.c_str()); } }
if (!std::filesystem::exists(input_pbf)) { SPDLOG_ERROR("输入文件: {} 不存在", input_pbf); return EXIT_FAILURE; }
for (auto &output_dir: output_dirs) { if (!std::filesystem::exists(output_dir)) { SPDLOG_INFO("输出目录: {} 不存在,自动创建……"); std::filesystem::create_directories(output_dir); } }
if (geojson_files.size() > 2) { SPDLOG_ERROR("目前只支持到ADM1级别"); return EXIT_FAILURE; }
std::vector<IGeoJSONFeature *> geojson_features; std::int32_t i = 0; for (i = 0; i < std::min((int)geojson_files.size(), 2); i++) { ADMLevel admLevel; if (i == 0) { admLevel = ADMLevel::ADM0; } else if (i == 1) { admLevel = ADMLevel::ADM1; } else { admLevel = ADMLevel::ADM2; } parse_geojson(geojson_files.at(i), admLevel, &geojson_features); } OuterGeoJSONFeature *outerGeoJsonFeature = new OuterGeoJSONFeature(); for (IGeoJSONFeature* feature: geojson_features) { InnerGeoJSONFeature* innerGeoJsonFeature = dynamic_cast<InnerGeoJSONFeature*>(feature); std::copy(innerGeoJsonFeature->coordinates.begin(), innerGeoJsonFeature->coordinates.end(), std::back_inserter(outerGeoJsonFeature->coordinates)); } geojson_features.push_back(outerGeoJsonFeature);
SPDLOG_INFO("GeoJSON已加载完成,总共: {}", geojson_features.size());
int fd; if (use_cache) { fd = ::open(index_path.c_str(), O_RDWR, 0666); } else { fd = ::open(index_path.c_str(), O_RDWR | O_CREAT | O_EXCL, 0666); } if (fd == -1) { SPDLOG_ERROR("open {} failed", index_path); return EXIT_FAILURE; } index_type index{fd}; location_handler_type location_handler{index}; location_handler.ignore_errors(); if (!use_cache) { auto start = std::chrono::system_clock::now();
SPDLOG_INFO("开始缓存节点信息"); osmium::io::File input_file(input_pbf); osmium::io::Reader reader(input_file, osmium::osm_entity_bits::all); osmium::io::Header header; CacheLocationHandler handler(location_handler); osmium::apply(reader, handler); reader.close();
auto end = std::chrono::system_clock::now(); // 计算耗时,单位为秒 std::chrono::duration<double> elapsed_seconds = end - start; SPDLOG_INFO("节点信息已经缓存完成, 耗时: {} 秒", elapsed_seconds.count()); }
threads_num = std::min(threads_num, static_cast<int>(geojson_features.size())); SPDLOG_INFO("will generate {} osm.pbf files, by {} threads", geojson_features.size(), threads_num);
std::vector<std::thread> threads; std::mutex output_mutex; // 用于线程安全地输出日志 int chunk_size = static_cast<int>(geojson_features.size()) / threads_num; // 每个线程处理的box数量
for (i = 0; i < threads_num; ++i) { std::int32_t start_index = i * chunk_size; std::int32_t end_index = start_index + chunk_size; if (i != (threads_num - 1)) { SPDLOG_INFO("start_index: {}, end_index: {}, chunk_size: {}", start_index, end_index, chunk_size); std::vector<IGeoJSONFeature *> boxes_chunk(geojson_features.begin() + start_index, geojson_features.begin() + end_index); threads.emplace_back(process_boxes_chunk, i, std::ref(output_dirs), std::ref(location_handler), boxes_chunk, std::ref(input_pbf), std::ref(output_mutex)); } else { SPDLOG_INFO("start_index: {}, to end", start_index); std::vector<IGeoJSONFeature *> boxes_chunk(geojson_features.begin() + start_index, geojson_features.end()); threads.emplace_back(process_boxes_chunk, i, std::ref(output_dirs), std::ref(location_handler), boxes_chunk, std::ref(input_pbf), std::ref(output_mutex)); } }
// 等待所有线程完成 for (auto &thread: threads) { if (thread.joinable()) { thread.join(); } }
SPDLOG_INFO("all osm.pbf files generated, begin to clean cache and free memory"); i = 0; for (auto feature: geojson_features) { if (InnerGeoJSONFeature* innerGeoJsonFeature = dynamic_cast<InnerGeoJSONFeature*>(feature)) { for (auto p: innerGeoJsonFeature->coordinates) { delete p; } }
delete feature; } if (!use_cache && std::filesystem::exists(index_path)) { std::remove(index_path.c_str()); } close(fd);
SPDLOG_INFO("all splitted completed"); return EXIT_SUCCESS;}2.3.1.3 按照bbox来切
Section titled “2.3.1.3 按照bbox来切”在github上有一款工具:osmcode/osmium-tool支持将OpenStreetMap数据(planet.osm.pbf)按经纬度范围(bbox)来提出该经纬度范围内的数据,但问题在于如果直接使用osmcode/osmium-tool的bbox来切割,我们将经度范围:-180~180,维度范围:-90~90,按一定步长(10或者20),这么笛卡尔积地组合以下,整个时间复杂度是:O(n^2)。就笔者实际测试来看,当步长是10的话,按此笛卡尔积地组合切割的话,需要一周时间;即使采用基于多核的CPU的并行切割方式,最快也需要3天时间。
因此,必须把这个时间复杂度下降到接近:O(1)。
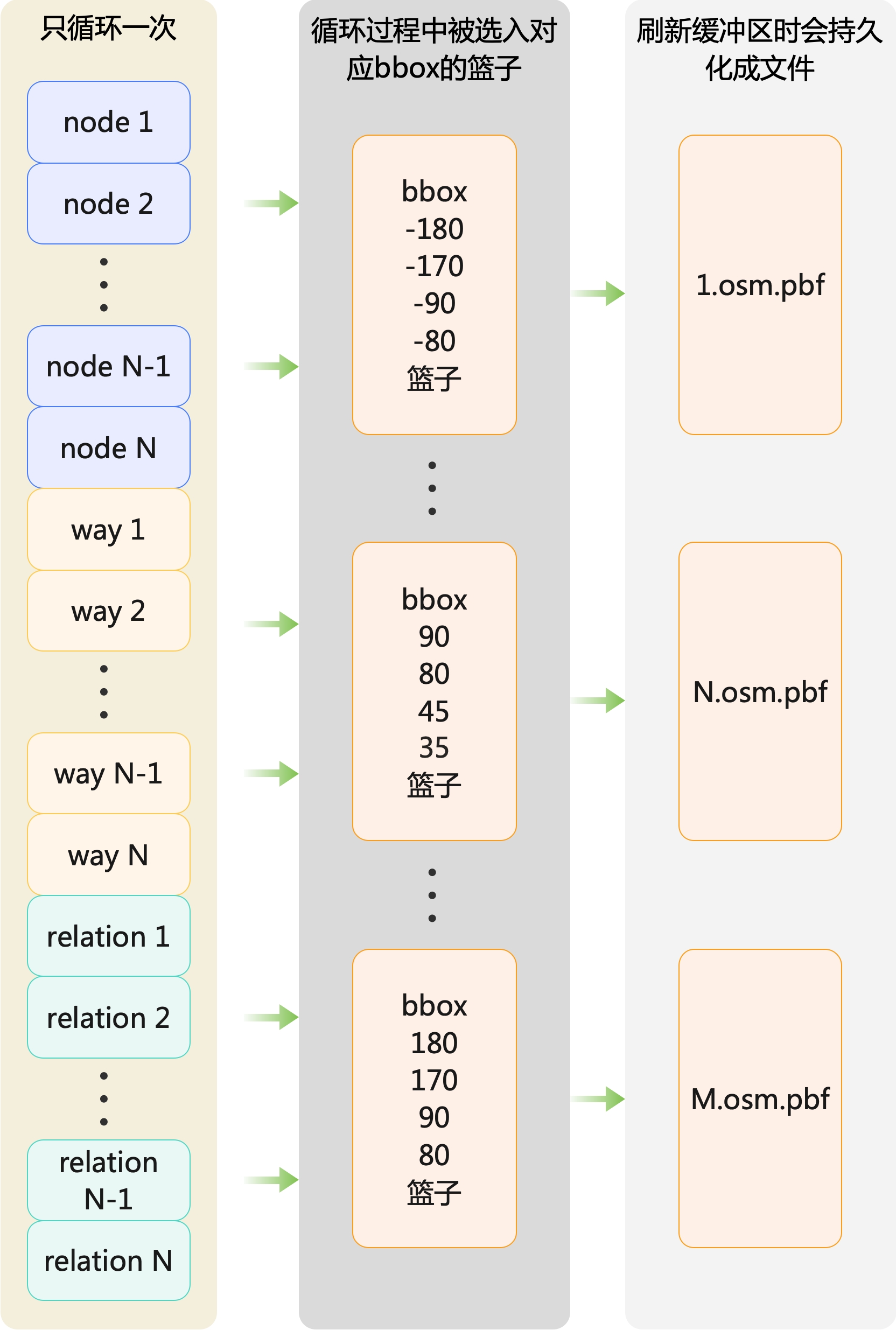
OpenStreetMap的地理数据本质是一个XML格式,在该XML中,包含三块信息:节点(Node)、路线(Way)、关系(Relation),这三种元素是构建OSM地图的基础,它们之间的关系十分紧密,共同描述了地图上的地理特征和地理实体。下面是内容参考:
<?xml version='1.0' encoding='UTF-8'?><osm version="0.6" generator="osmconvert 0.8.10"> <node id="3387792987" lat="30.2749727" lon="120.186591" version="2" timestamp="2015-04-12T13:21:35Z" changeset="0"/> <way id="331677437" version="9" timestamp="2024-05-25T04:06:18Z" changeset="0"> <nd ref="3387792987"/> <nd ref="3452151973"/> <nd ref="3463697268"/> </way> <relation id="17634728" version="1" timestamp="2024-05-25T04:06:18Z" changeset="0"> <member type="way" ref="288874844" role="part"/> <member type="relation" ref="9346819" role="part"/> <member type="way" ref="28907128" role="part"/> <member type="way" ref="331677437" role="part"/> <member type="way" ref="506752910" role="part"/> <member type="way" ref="482783619" role="part"/> <member type="way" ref="549787945" role="part"/> <tag k="name" v="浙江大学"/> <tag k="name:en" v="Zhejiang University"/> <tag k="name:zh-Hant" v="浙江大學"/> <tag k="short_name:en" v="ZJU"/> <tag k="site" v="university"/> <tag k="type" v="site"/> <tag k="wikidata" v="Q197543"/> <tag k="wikipedia" v="zh:浙江大学"/> </relation></osm>- 节点(Node):
- 节点是OSM地图中的基本元素之一,代表地图上的一个具体位置。
- 每个节点由一个唯一的ID和一对经纬度坐标定义。
- 节点可以独立存在,表示地图上的某个特定地点,如兴趣点(POI),或者与其他节点结合,形成更复杂的结构,如路线或多边形。
- 路线(Way):
- 路线是由两个或多个节点按特定顺序连接形成的线性结构。
- 路线可以表示实际的物理现象,如道路、河流或公园的轮廓。
- 路线既可以是开放的线段,也可以是闭合的环形,闭合路线通常用来定义区域(如建筑物或湖泊的边界)。
- 关系(Relation):
- 关系是OpenStreetMap中用来描述元素之间复杂关系的结构。
- 关系可以包含节点、路线以及其他关系,它们通过”角色”来定义各元素在关系中的作用。
- 常见的关系类型包括公交路线(由多条路线和站点节点组成),限制(如行驶方向限制),或多边形的多部分(例如,一个由多个岛屿组成的国家)。
以上述实例的XML数据为例,id为17634728的relation元素,它的名称是浙江大学,它其中有一个way的id是:331677437。而这条id为331677437的way涉及的其中一个node是3387792987。因此,我们需要把id为17634728的relation和id是331677437的way,都放入id是3387792987的node所在的同一个篮子中。即下图所示:
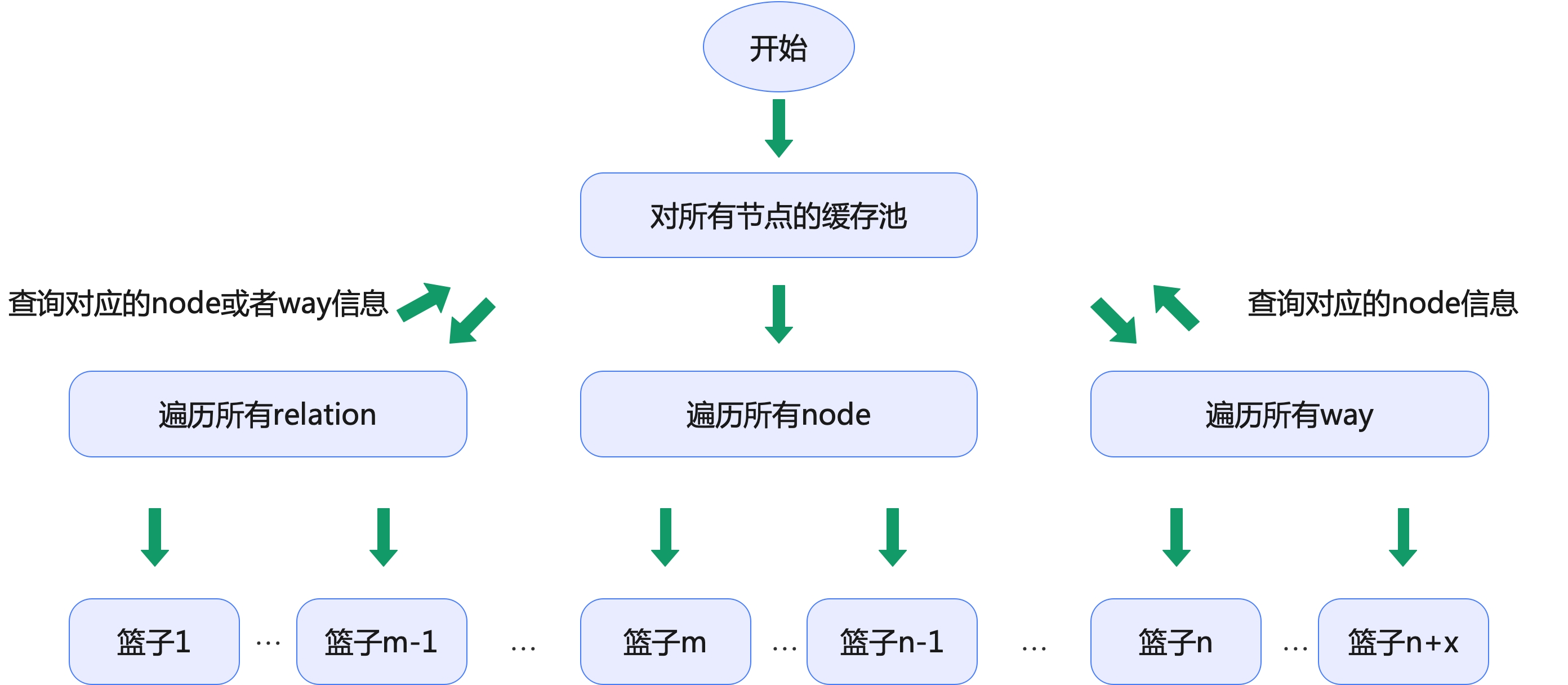
我们不单单需要将各个Node选入各自的bbox篮子中,相应的Way和Relation也要选入其关联Node的bbox篮子中。
2.3.2 mapper阶段快速将数据导入到目标PostgreSQL中
Section titled “2.3.2 mapper阶段快速将数据导入到目标PostgreSQL中”首先,在上述对全球OpenStreetMap的数据切割成N多份后,下面我们基于Hadoop来构建并发任务,因此会将切割后的数据都转存到HDFS上暂存。本装置的mapper从HDFS上读取切割后的数据开始,单个mapper的核心逻辑下图所示:
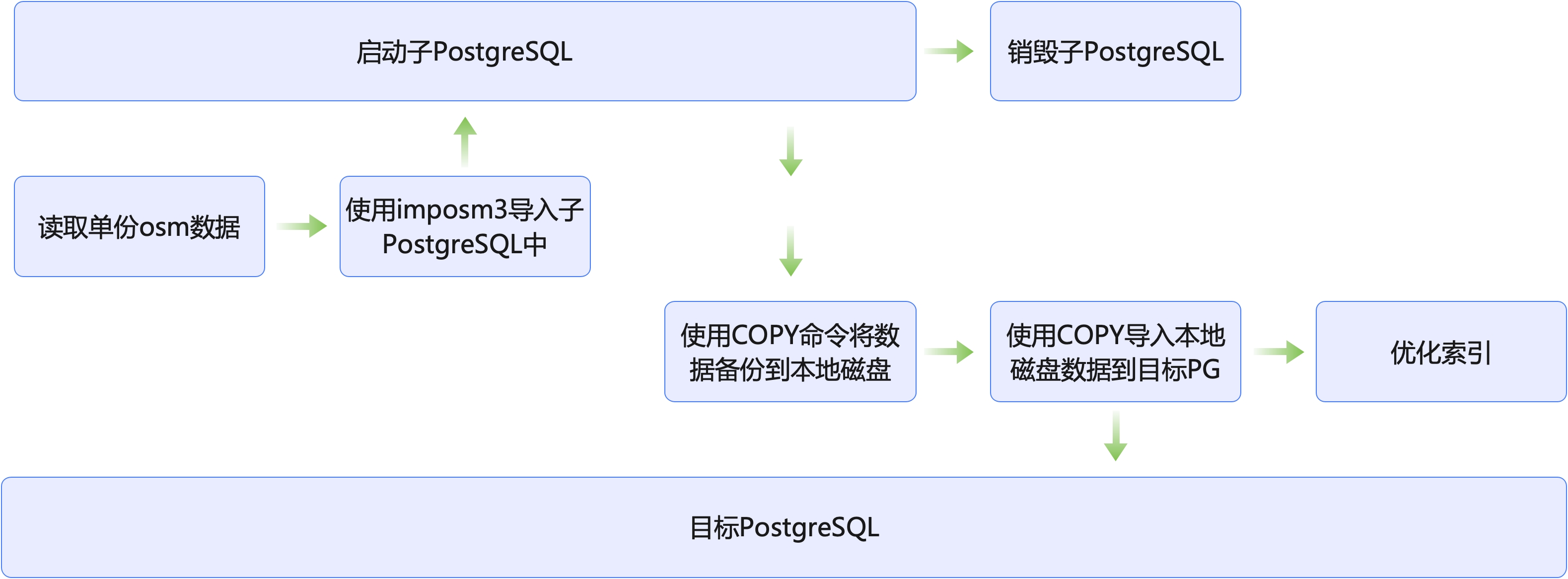 核心的Mapper逻辑是这样的:
核心的Mapper逻辑是这样的:
- 每个Mapper都会启动一个PostgreSQL实例,用于接受这次子任务的数据导入
- 依旧通过imposm3来将该mapper的osm.pbf数据导入到该PostgreSQL实例中(并且不创建索引)
- 然后通过PostgreSQL的COPY语句将成功导入的数据导出到本地磁盘
- 上述这个临时的PostgreSQL实例已经无用了,可以销毁它了。
- 将刚才缓存到本地磁盘上的导出数据,通过使用目标PostgreSQL的COPY语句导入进去。
- 进行索引优化
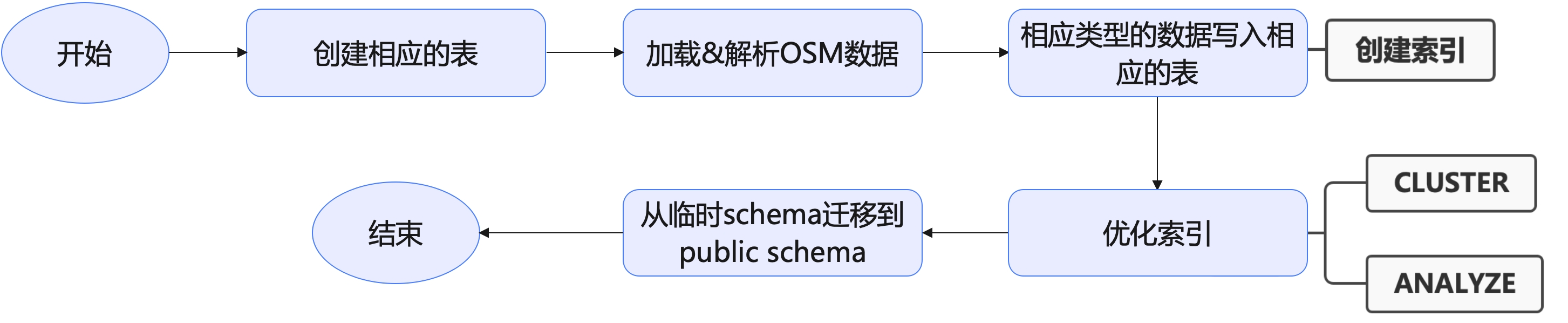
2.3.3 整体流程总结
Section titled “2.3.3 整体流程总结”我们的核心点在于从单机改成了基于Hadoop的并行导入,极大提升了优化性能。除此之外,在数据导入的前后也做了很多外围工作,整体流程如下:
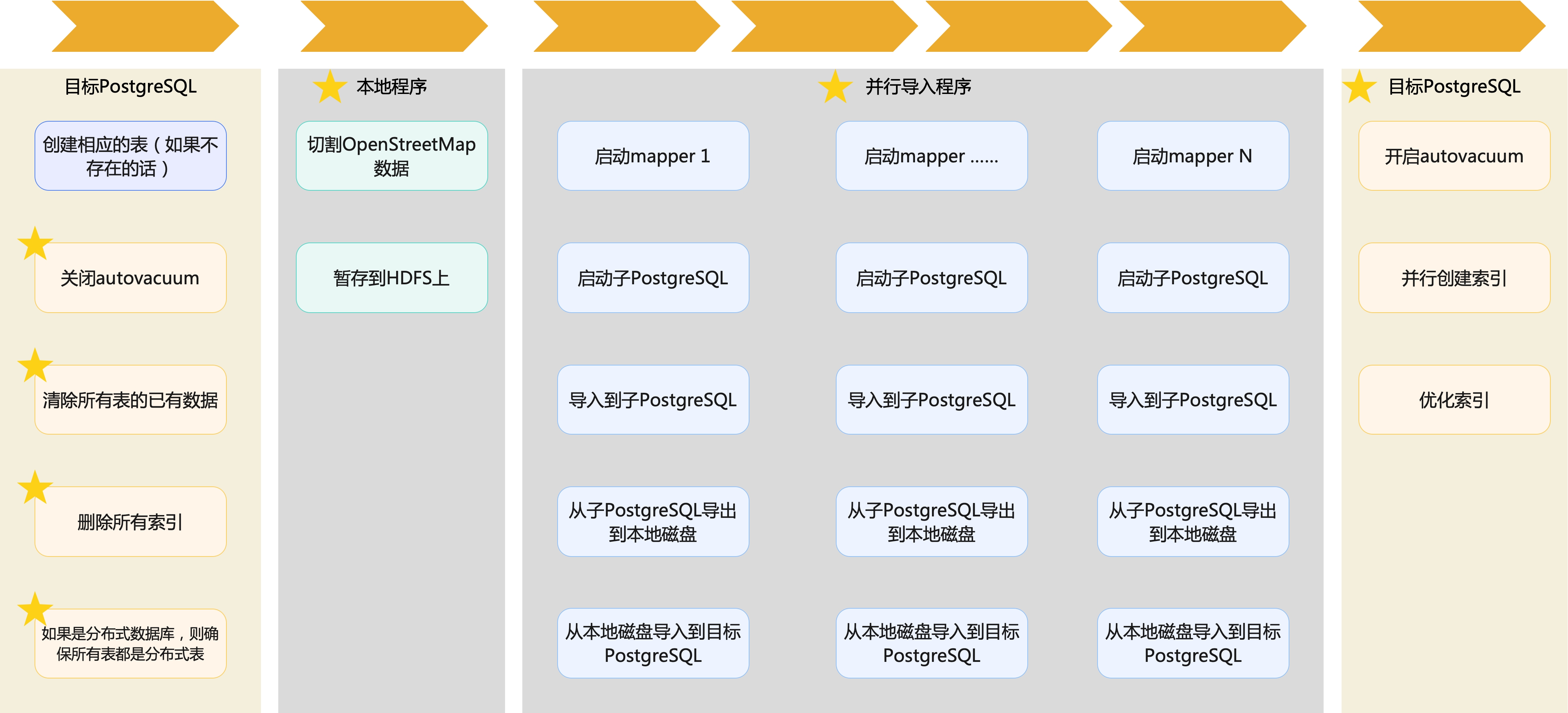
并且,为了最大化地对整个流程进行优化,在导入过程的前后也做了诸多优化,包括:
- 在开始导入前:
- 关闭autovacuum
- 清楚所有表的已有数据
- 删除所有索引
- 如果是分布式数据库,则确保所有表都是分布式表
- 在结束导入后:
- 开启autovacuum
- 并行创建索引
- 优化索引
通过上述整体的优化,对全球OpenStreetMap地图数据的瓦片数据转换,从需要一周多,优化到只需要2.5小时,性能提升显著。